「正規表現」を使ってデータを加工してみよう 【文学・歴史資料のデジタル加工入門1】(木越 治)
【キャラクタクラスの使い方】
で、私はこれのうしろに 「+」 を付けている。この「+」は
直前の文字集合の一回以上の繰り返し
を意味するメタ文字である。つまり、この「+」をつけるだけで、
[0-9]
[0-9][0-9]
[0-9][0-9][0-9]
[0-9][0-9][0-9][0-9]
……(以下無限に続く)
というふうに、これらのどれにでもマッチするようになるのである。つまり、
[0-9]
だけだと、一桁の数字
[0-9][0-9]
これは二桁
[0-9][0-9][0-9]
これは三桁の数字、ということがわかれば、
[0-9]+
にすると、何桁の数字でもOKということがわかっていただけると思う。
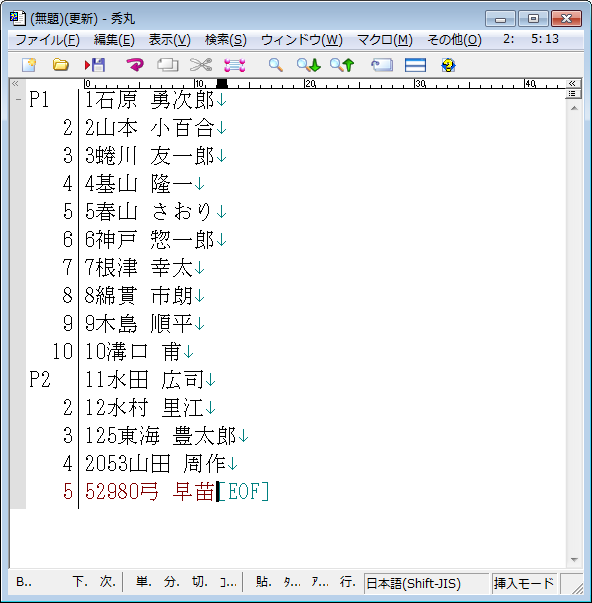
試しに、さきほどデータに、3桁~5桁のデータを足してやってみよう。
 ======================
======================
1石原 勇次郎
2山本 小百合
3蜷川 友一郎
4基山 隆一
5春山 さおり
6神戸 惣一郎
7根津 幸太
8綿貫 市朗
9木島 順平
10溝口 甫
11水田 広司
12水村 里江
125東海 豊太郎
2053山田 周作
52980弓 早苗
======================
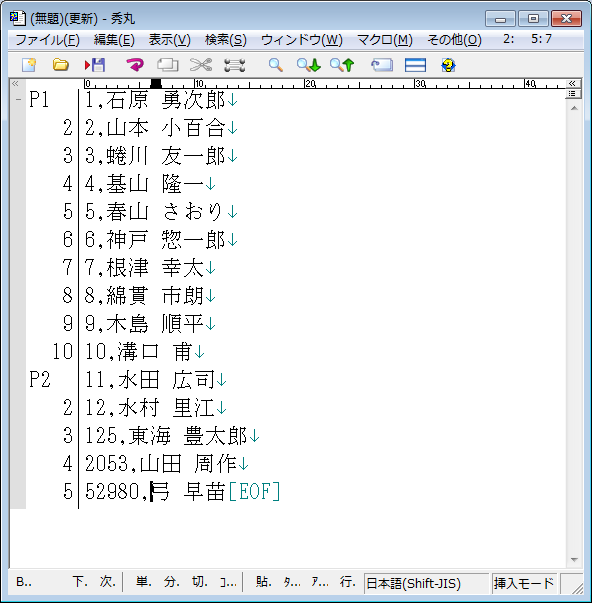
これに、さきほどの置換を実行すると
 ======================
======================
1,石原 勇次郎
2,山本 小百合
3,蜷川 友一郎
4,基山 隆一
5,春山 さおり
6,神戸 惣一郎
7,根津 幸太
8,綿貫 市朗
9,木島 順平
10,溝口 甫
11,水田 広司
12,水村 里江
125,東海 豊太郎
2053,山田 周作
52980,弓 早苗
======================
となり、問題なく成功している。
要するに、[1-9]を( )でくくった置換前の文字列
([1-9]+)
は、半角数字が何桁続いていても、その半角数字の文字列集合自体をあらわすことになる。そして、置換後文字列にある
\1
は、正規表現で表された置換前文字集合の一番目のものを意味している。いまは文字集合がひとつしかないのでわかりにくいと思うが、置換前文字列の中には、正規表現の文字集合を何種類でも指定可能なのである。それで出現順に、\1 \2 というふうに並べることになっているのだが、複数使うときにはいろいろ面倒な約束事が出てくるので、当面はひとつの例だけにしておく。だから、\1 は、置換前の文字集合そのものを意味するおまじないみたいなものと思っていてかまわない。
いずれにしても、こうすれば、もとの出席番号が、「11」ならば、置換後もそのまま「11」と返してくれるし、「2598」ならそのまま「2598」を置換後に返してくれるのである。これが使えるのと使えないのとでは、作業効率に大きな違いが出ることは、もうおわかりだろう。