「正規表現」を使ってデータを加工してみよう 【文学・歴史資料のデジタル加工入門1】(木越 治)
【紙媒体資料をデータファイル化する】
まず、先月末に試みた、以下のような例を紹介することから始めることにしよう。
いま私は、さる私立の中学校で週二回計8時間、3年生相手に古文を教えている。中間試験の時期になったので成績を記入するために、係から学生(生徒)名簿を記入した短冊をもらってきた。(いま、大学関係では、成績やシラバス記入は、たいていWebから入力するシステムになっている。だから、受講者名簿は簡単にダウンロードできるが、中学や高校くらいだと、成績入力はコンピュータでやっても、外部には公開しないシステムのところが多い。大学と違い、教員はほぼ毎日出講するから、あまりその必要がないのだろうし、セキュリティ上もその方が安心である。係の人にも聞いてみたが、事務室では紙媒体でしか渡せないということだった。)
で、まあ、これを自分でなんとかデータファイル化しようというのが、今回のテーマである。
もちろん、時間と手間を惜しまなければ、Excelに直接名前を打ち込んでいけばいいわけである。しかし、大学のゼミや演習程度の人数(20人~30人)ならたいした手間ではないが、この学校の1学年の人数は170人近くいる。これだけの人名を自分で入力する気にはとてもなれない。紙媒体のまま成績ノートに貼り付けて管理している先生もいるようだが、私としては、あとあとのためにもデータファイル化しておきたいのである。
これをファイルにするための作業手順は、以下のようになるだろう。
1.名簿をスキャンして、PDF化する。
2.できたPDFファイルをOCRソフトで読み取り、文字データ(プレーンなテキストデータ)化する。
3.そのテキストファイルをExcelに読み込む。
1の処理は、10年近く使っているScanSnapで行なった。また、OCRソフトは「読取革命」を用いた。「読取革命」は、読み取り能力が特にすぐれているとも思えないが、PDFファイルをダイレクトに読み込んで処理してくれる点が便利なので使っている。私はあまり使わないが、Acrobat(Rederではなく、有料の方)にはファイルに文字列を書き出す機能があるらしいので、それを使うのもいいと思う。なお、読取革命は、いろいなアプリケーションの形式に対応するとうたっているが、実際にはあまり使えない。結局は、プレーンなテキストファイルにするのがいちばん汎用性がある。
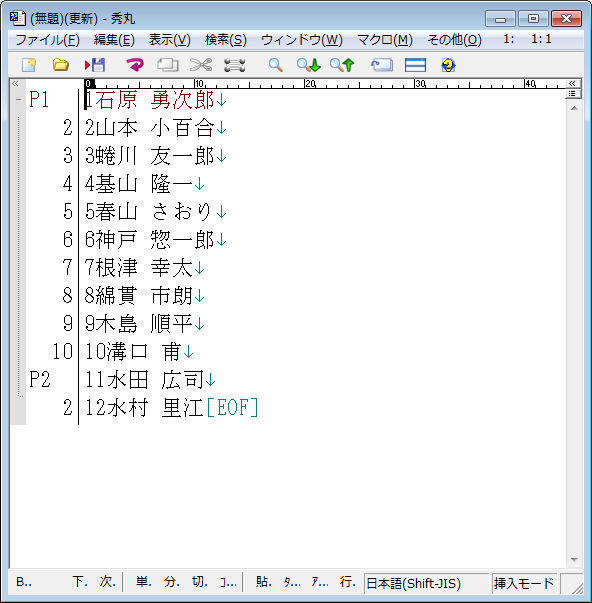
その結果、出来あがったファイルは以下のようになった。(ただし、人名データなので、そのままを出すことは控え、架空の名前に差し替えてある。またデータ数も170ちかくあるが、見本なので、20人程度にとどめた。)
 =========================
=========================
1石原 勇次郎
2山本 小百合
3蜷川 友一郎
4基山 隆一
5春山 さおり
6神戸 惣一郎
7根津 幸太
8綿貫 市朗
9木島 順平
10溝口 甫
11水田 広司
12水村 里江
=========================
このデータを、このままExcelに読み込ませると、文字データである名前と数字データである出席番号がいっしょになってしまう。
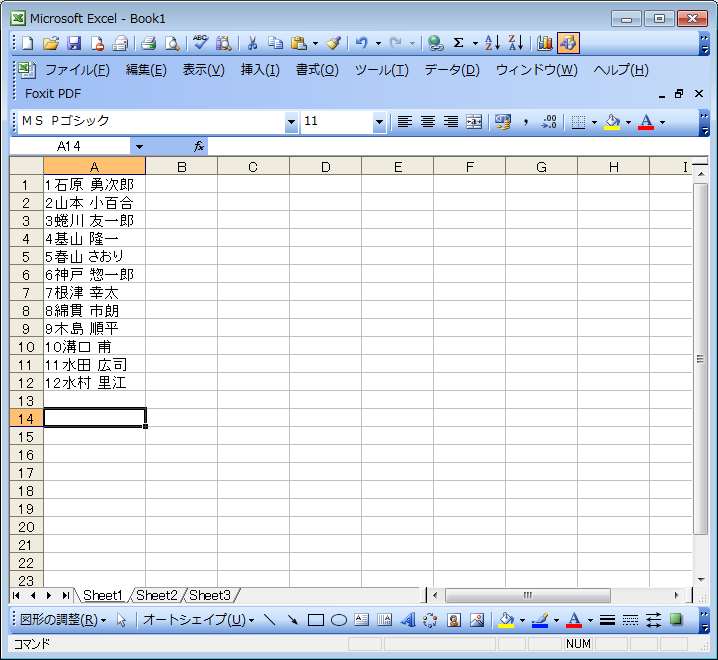 これは具合が悪い。この種のデータにおいては、文字データと数字データをフィールドとして区別しておく方が絶対的に便利である。そうしておけば、得点順や問題別の得点分布などを簡単にソートして見ることができるし、もとの出席番号順にもどすのも簡単である。そのためには、数字のあとに「,」(半角)をつけておくのがいい。Excelは「,」をフィールド区切り文字と認識し、名前の部分と区別して読み込んでくれるからである。
これは具合が悪い。この種のデータにおいては、文字データと数字データをフィールドとして区別しておく方が絶対的に便利である。そうしておけば、得点順や問題別の得点分布などを簡単にソートして見ることができるし、もとの出席番号順にもどすのも簡単である。そのためには、数字のあとに「,」(半角)をつけておくのがいい。Excelは「,」をフィールド区切り文字と認識し、名前の部分と区別して読み込んでくれるからである。
そして、この作業をするときに、「正規表現を用いた文字グループによる置換」を利用すると一瞬で作業が終わってしまうのである。